Understanding the Multi-Language Large Model Data Development in the Big Model Era
Context
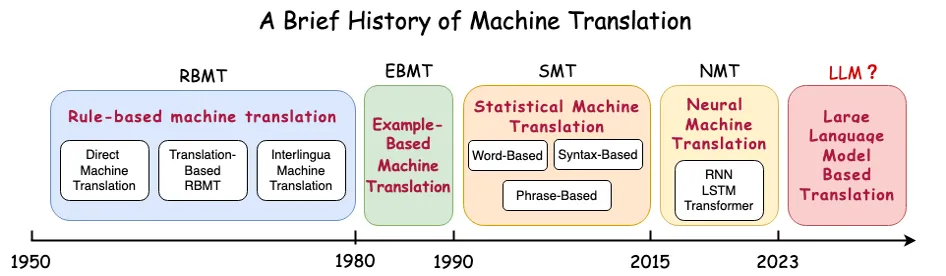
Following the release of ChatGPT 3.0 by OpenAI on November 30, 2022, large models have experienced explosive growth, significantly elevating the importance of AI. This surge has been characterized by resource allocation, AI startup companies, and major corporations raising AI to a strategic level, the "hundred models war," and large-scale inference applications. At the heart of these developments is data, with training data becoming a core element of model effectiveness. The AICon (Global Artificial Intelligence Development and Application Conference) often features technical sessions on large model data.
Alibaba International Digital Commerce (AIDC) is a cross-border e-commerce group with primary operations in cross-border e-commerce, including businesses such as AliExpress, Lazada, Alibaba International Station ICBU, Trendyol, Daraz, and Miravia. Against this backdrop, AIDC has developed multi-language large models to enhance efficiency and address challenges encountered in business development, focusing on content localization, global user services, and global marketing in multi-language scenarios. A typical business scenario for large language models is translation, which has been dominated by Neural Machine Translation (NMT) technology in recent years and holds significant opportunities for large model-based translation.
Current Industry Translation Technology Levels
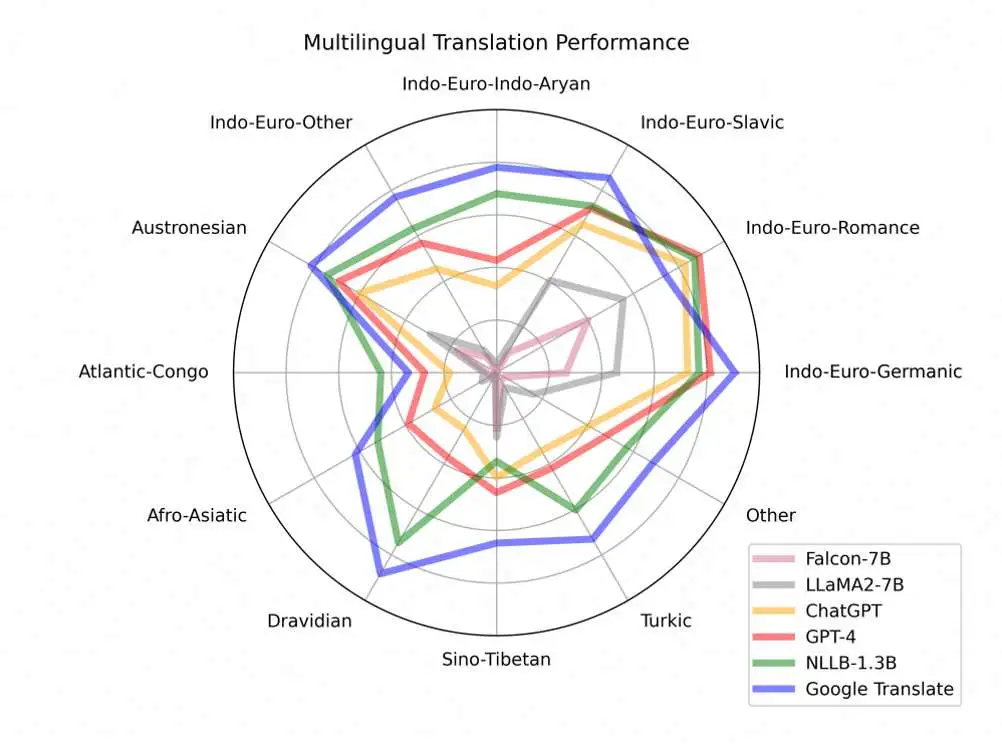
The performance of translation technologies across various language families is illustrated in the figure below. It is clear that Google Translate, with its core technology based on NMT, performs strongly, while GPT-4 excels in some language families but still lags significantly in others. AIDC's international multi-language translation large model initiative began in this technological and business context.
Large Model Data Cleaning
Characteristics of Large Model Data
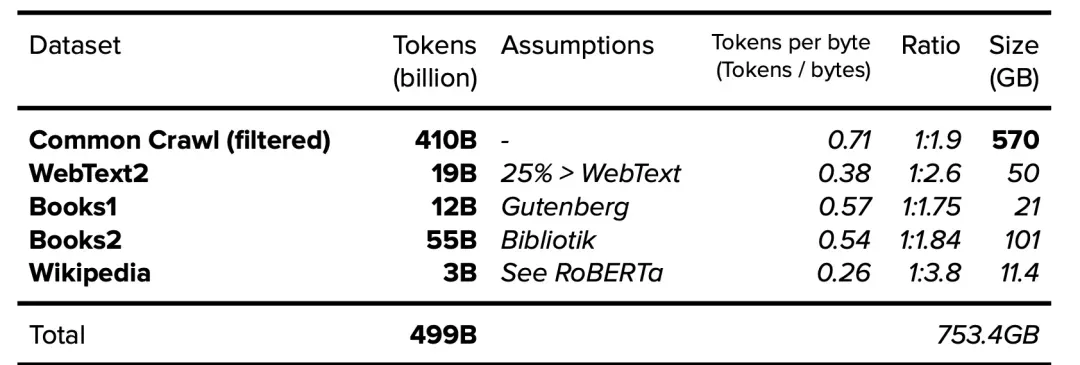
The importance of data has been repeatedly emphasized, with data often likened to oil, highlighting its significance. Before the era of large models, the term "data" was more associated with operational data such as products, customers, consumption, transaction orders, payments, logistics, etc. During this phase, the market often discussed precision marketing, risk control, sales forecasting, and inventory optimization, which were data-driven intelligent cases. This phase of data is defined from a business perspective as operational data, characterized by structured business data and data processing technologies such as distributed data computing and offline real-time computing, using engines similar to Hadoop and Spark, collectively referred to as data warehouses or data platforms. In the era of large models, the definition of data has undergone a significant change. Observing the public training data list of ChatGPT3.0, as shown in the figure below,
Llama3's public training data scale exceeds 15T Tokens, and DeepSeek3's public training data scale is 14.8T Tokens.
There are two significant changes here: 1) the data measurement unit Token 2) the data is not internal operational data of enterprises. This implies that tasks at various stages of the data lifecycle, including data collection, data scope, data structure, processing methods, and data usage, have undergone substantial changes.
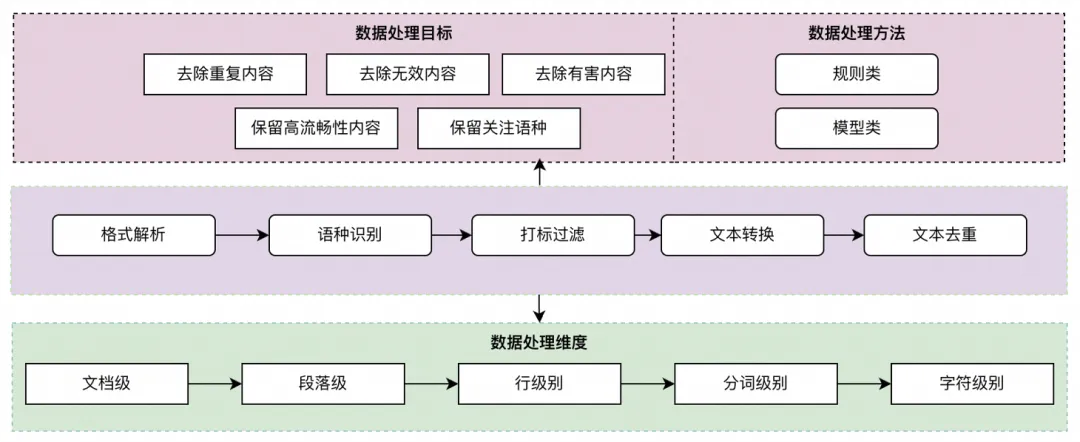
Multi-Language Large Model Development Data Overall Process
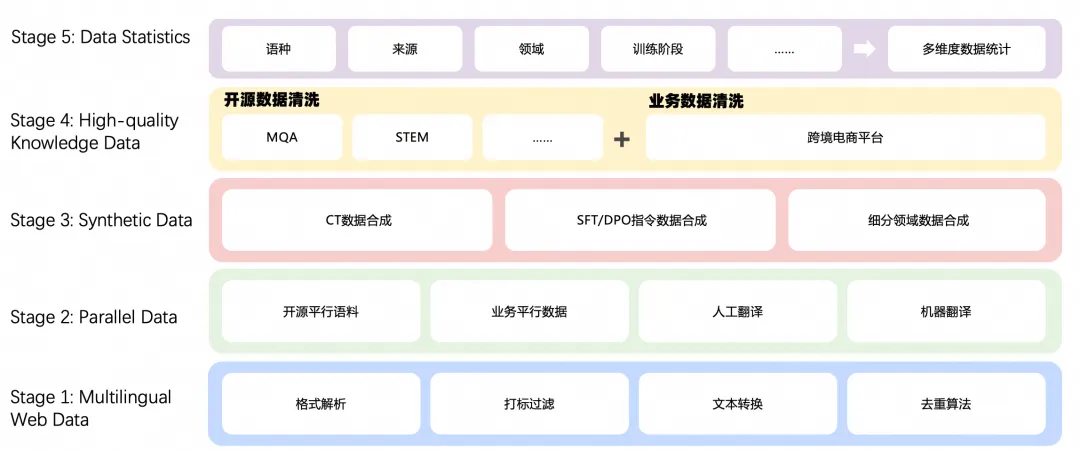
The core of multi-language large model development is to address multi-language data issues. In the entire development process, we focus on four aspects to solve multi-language data: 1) global multi-language web page data acquisition and processing, 2) parallel corpus acquisition and processing, 3) multi-language data synthesis, and 4) the use of accumulated business data.
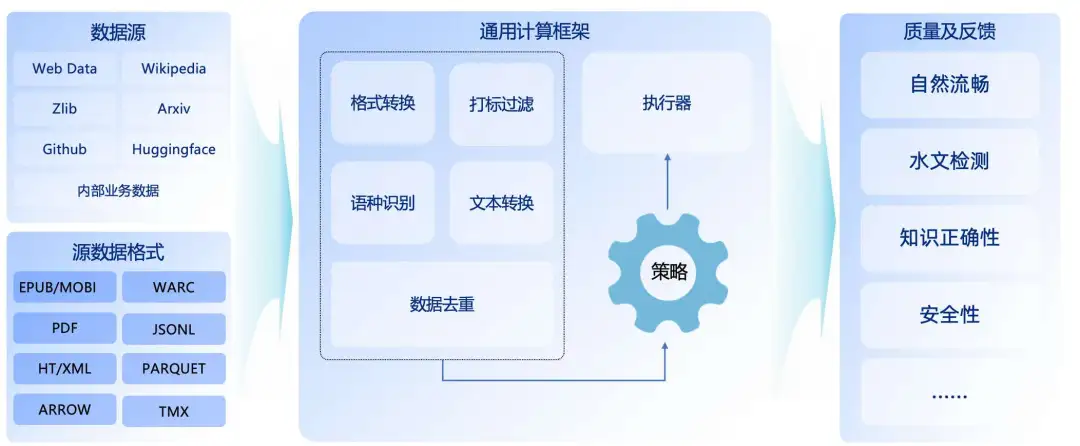
Multi-Language Data General Processing Framework

In the various stages of model training, such as CT, SFT, and DPO, basic data processing methods are involved. Therefore, we abstract these basic processing methods and design a general data computation processing framework that incorporates multi-language computation logic, such as language identification, grammar for each language, and punctuation for each language.
Processing Process Based on the General Framework
For different data, we use this general computation framework and perform certain processing afterward. For example, the processing flow for multi-language data involves using the general computation framework to configure execution strategies, format conversion, tagging filtering, language identification, text conversion, and data deduplication. After computation with the general framework, a series of quality and feedback methods are used to ultimately produce multi-language training corpora.
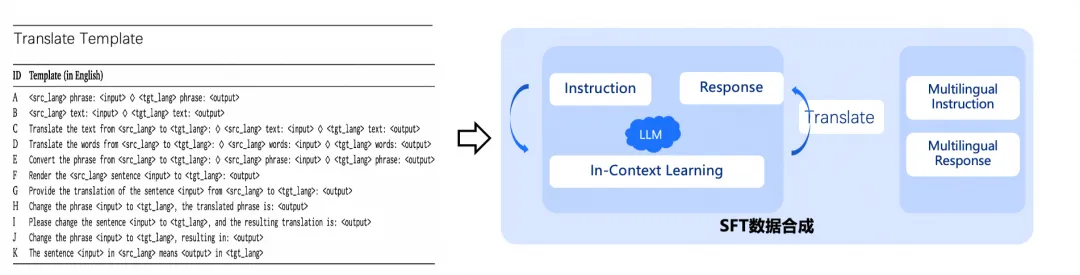
Parallel Corpus Synthesis
Parallel corpora utilize open-source data corpus cleaning, such as OPUS and CCAligned, and a significant amount of expert translation, serving as the core parallel corpus data. Building on this foundation, on one hand, we use seed words to generate training data based on keywords and thematic attributes; on the other hand, we synthesize parallel corpora based on monolingual multi-language data, designing Translate Templates to enhance input diversity, and using In-Context Learning and multi-language translation technology to generate multi-language data, thereby strengthening semantic alignment between multi-language parallel sentences. From practical experience, parallel data is crucial for enhancing the multi-language capabilities of LLMs, especially for translation tasks.
Data Synthesis Based on Keywords
Synthesis of Parallel Corpora Based on Translate Templates
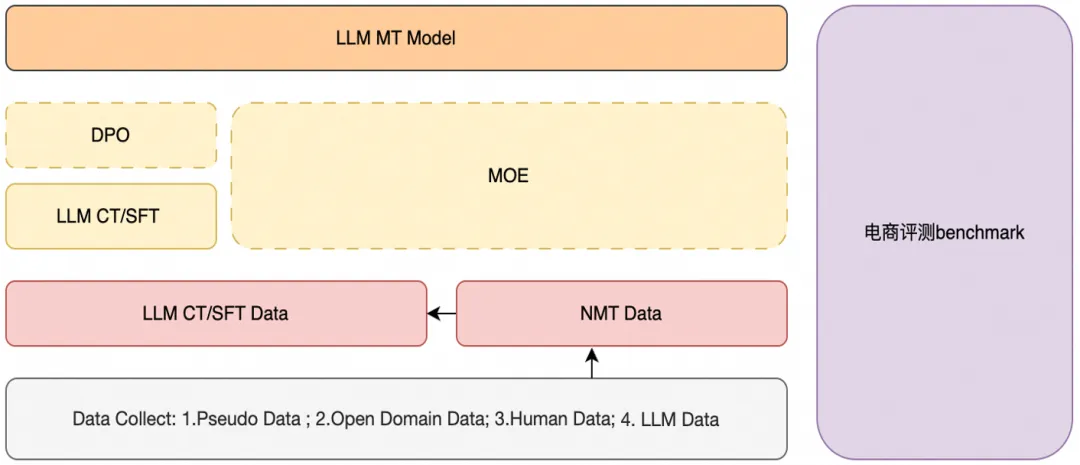
Multi-Language Large Model Data Application Examples
Macro-MT Data Application
E-commerce translation CT is based on a large amount of e-commerce corpora such as titles, details, comments, dialogues, and searches to construct the foundation of the multi-language translation large model, currently supporting over 20 languages. E-commerce translation SFT enhances LLM translation effects by incorporating high-quality parallel corpora, while the translation results also possess a certain e-commerce style. E-commerce translation preference alignment uses specific preference data for training to alleviate LLM translation hallucination issues and improve the translation effects of words unique to translation scenarios.
In model training, we adopt a two-stage CT learning method aimed at facilitating the transfer of common-sense knowledge, primarily obtained in English and Chinese, to various low-resource languages and specific NLP downstream tasks such as machine translation. In terms of continuous pre-training, data mixing and learning rate are two key hyperparameters for optimizing Marco. In our practice, we use different hyperparameters in the two-stage training. Specifically, we select mixed data to balance the multi-language capabilities in the first stage and the adaptability to catastrophic forgetting, while the goal of the second stage is to further enhance Marco-LLM's multi-language capabilities by reducing the maximum learning rate.
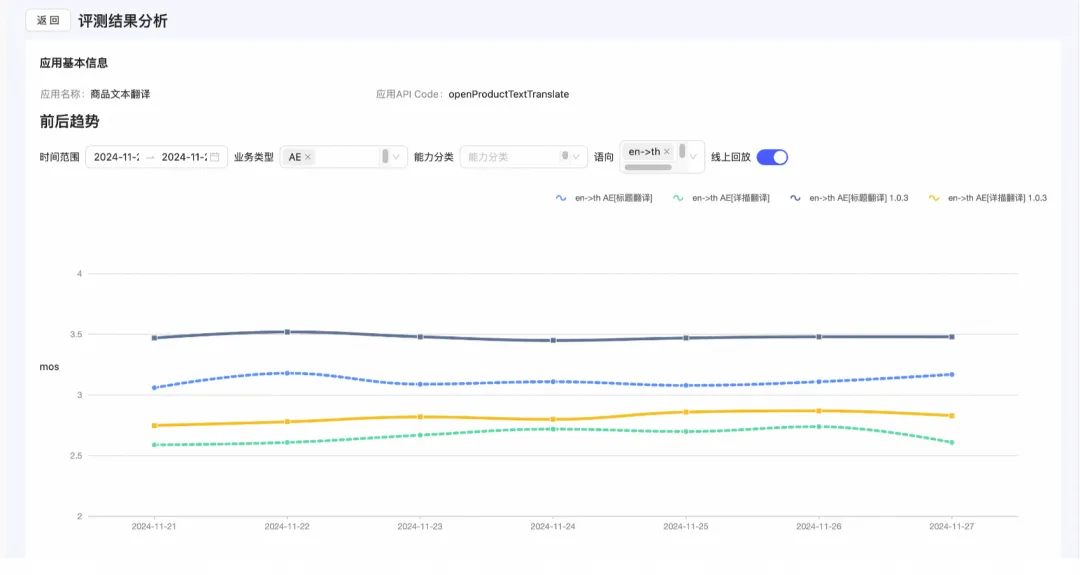
Large Model Evaluation
Model evaluation is a crucial part of model development and iteration. By evaluating the model on multi-language domain general Benchmark assessments and supplementing corresponding language and language direction data, we can improve model performance. In terms of model business evaluation, we use Human Feedback as Ground Truth to train the referee model, thereby obtaining the ability to automatically evaluate model business performance. By constructing a multi-language model business evaluation set and combining manual and model evaluations, we can supplement data in segmented business scenarios to enhance model business performance.
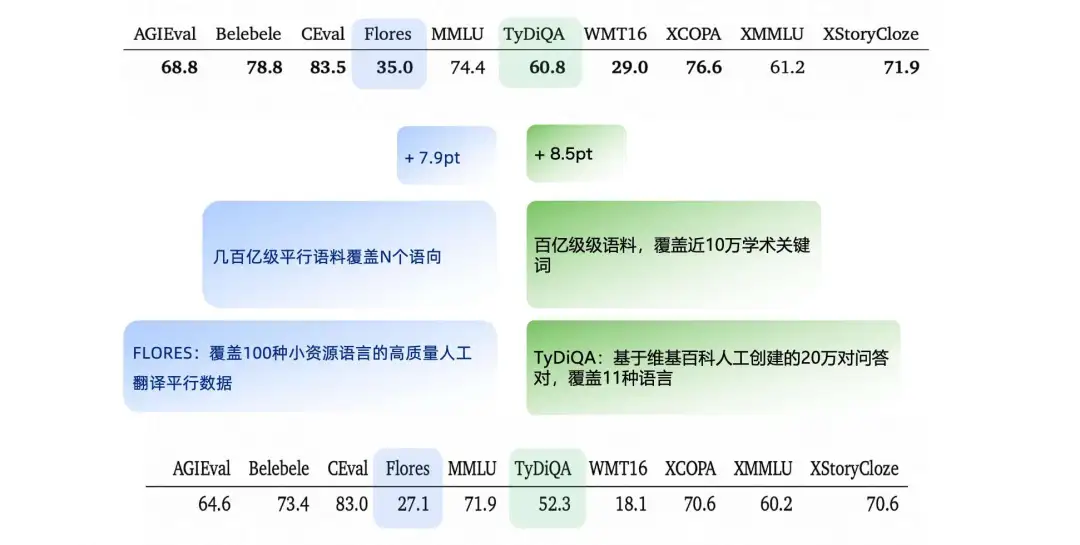
In a general Benchmark evaluation, our model has significant room for improvement on the Flores and TyDiQA Benchmarks, so we increase the corresponding training corpora to enhance model performance.
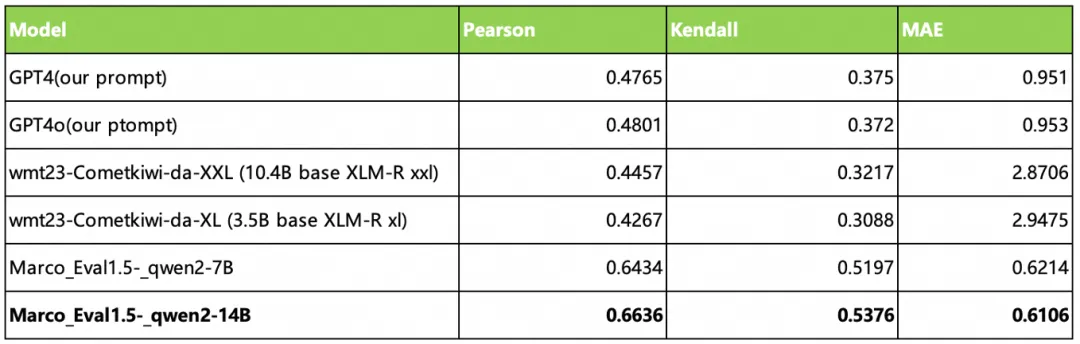
For our own cross-border e-commerce business, we extensively use LLM and MLLM capabilities, and the model's performance on Benchmarks in the cross-border e-commerce business field is even more critical. The model's performance in Alibaba International's AliExpress, Lazada, ICBU, and other business areas, such as product translation, marketing, dialogue, and search, is evaluated using our self-developed referee model, combined with RAG and Prompt Engineering methods, for pre-launch model business area evaluation, multi-version effect comparison, post-launch routine inspection, BadCase identification, and attribution analysis. The referee model trained with Qwen can effectively conduct automated evaluations in various dimensions such as Pearson, Kendall, and MAE, and is continuously being optimized and iterated.
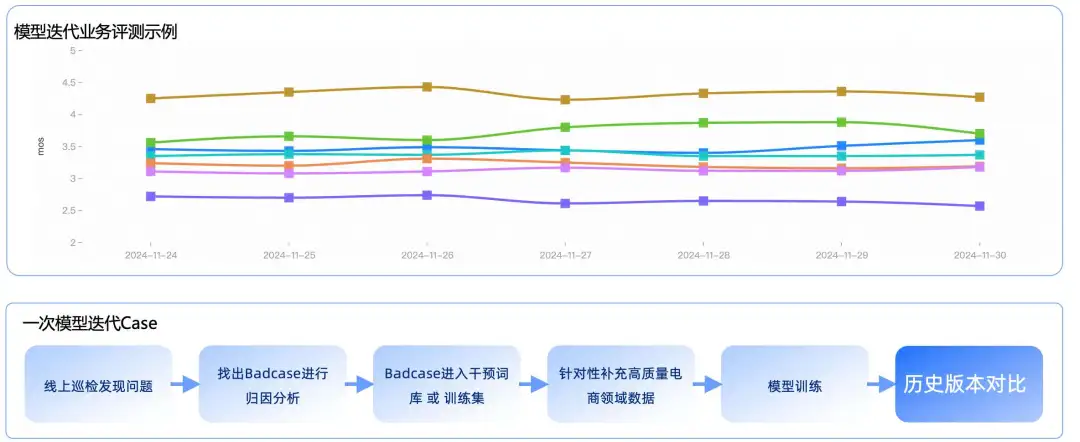
In the model iteration process, we often go through multiple steps, as shown in the figure below, which is a daily model iteration case.
During each model iteration release, we replay historical business data against the model's effects, and only if the effects are better than the previous version is the model allowed to be released.
Future Challenges
Since the release of ChatGPT 3.0 over two years ago, the basic capabilities of large language models and multi-modal models have become increasingly strong, with more and more companies turning to large model-centric AI system construction to serve and expand their businesses.
The construction of AI application systems poses higher challenges for large model data. In the Foundation Model development phase, the core of large model data is to meet the requirements of model training in terms of quantity, quality, and diversity. In AI application development, large model data is about higher-quality data in professional fields, presenting two fundamental challenges:
1. Cleaning out data from a vast sea of data for a specific business field. Cleaning out designated business data from a vast amount of data requires more computing power and more precise algorithms for identification. For example, selecting paintings in the style of traditional Chinese painting from billions of images requires scanning all images and having good algorithm performance for style determination. Similarly, cleaning out humorous and cold joke corpora from PB-level trillions of Token text data while removing pornographic and violent content involves huge computational efforts and higher text content understanding capabilities.
2. Integration, cleaning, and quality enhancement of business field data. Every enterprise has various data accumulations, including requirement documents, design documents, product manuals, code repositories, launch records, customer service, transaction generation, machine resources, personnel management, and customer management, among many other types of data. Processing these data is not just about format cleaning tasks and content aggregation tasks; the greater challenge lies in linking the business meanings of the data, such as linking requirement documents with product features, product features with launch records, and product features with user behavior. In the AI era centered on large models, these data not covered by data warehouses are undoubtedly valuable assets.
From Foundation Model to AI application, from large-scale training to business field Post Training, from broad data to business field data, higher requirements and challenges are posed for data. Let us explore and practice large model application data together to embrace the widespread blooming of AI applications.