Ollama v0.8 has arrived with groundbreaking upgrades, setting a new benchmark for running large language models (LLMs) locally. This latest iteration not only enhances the user experience through real-time interaction but also expands the capabilities of local AI, making it a formidable contender in the AI ecosystem.
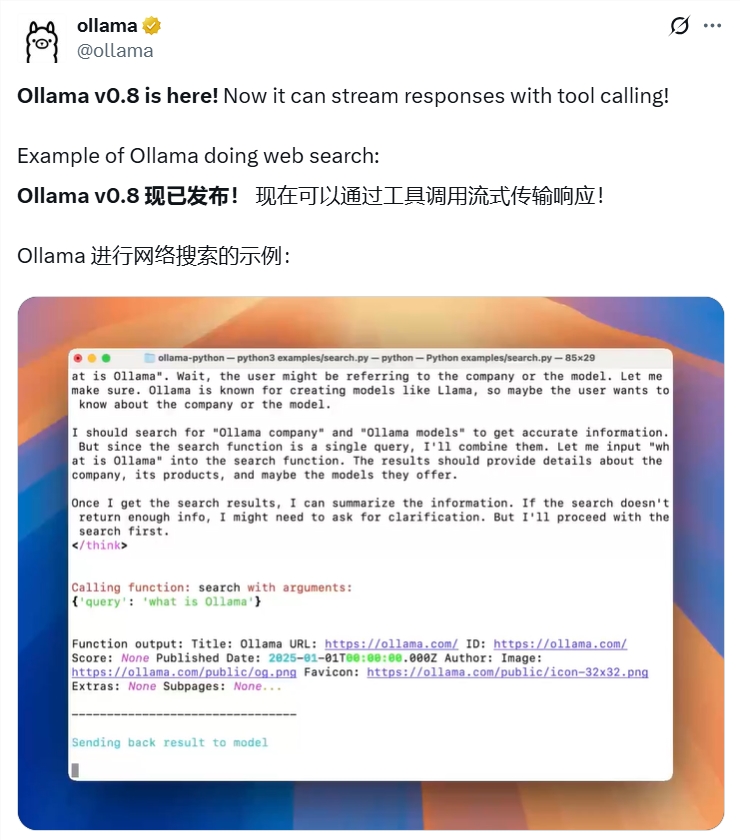
The introduction of streaming response functionality in Ollama v0.8 allows for a more dynamic interaction, providing users with a glimpse into the AI's thought process as it generates responses in real-time. This feature is particularly beneficial in complex queries and long-form text generation, significantly reducing wait times and offering a smoother conversational flow. Imagine conducting a web search and witnessing the AI's step-by-step approach to presenting results, a testament to the efficiency gains this version promises.
Beyond mere conversation, Ollama v0.8's tool invocation feature bridges the gap between local AI and the external world. By interacting with external tools and data sources via APIs, local language models can now perform tasks that were previously confined to cloud-based AI. This functionality transforms the local AI from a static responder into a dynamic, real-time intelligence assistant, capable of fetching live data or connecting to other services such as databases and third-party tools.
Ollama v0.8 also delivers a performance boost, addressing memory leak issues in models like Gemma3 and Mistral Small3.1, and optimizing model loading speeds, especially on network-supported file systems. The addition of sliding window attention optimization further enhances Gemma3's long-context reasoning and memory efficiency.
In line with its open-source ethos, Ollama v0.8 continues to empower developers and the community. The official GitHub repository offers complete code and documentation, supporting a variety of mainstream models. With simple commands, developers can run these models locally, bypassing cloud APIs and balancing privacy with cost-effectiveness.
Ollama v0.8's open-source framework also previews support for AMD graphics cards across Windows and Linux, and through initial compatibility with OpenAI Chat Completions API, it allows developers to seamlessly integrate existing OpenAI tools with local models. This openness and compatibility lower the barrier to entry, inviting more developers into the Ollama ecosystem.
The release of Ollama v0.8 solidifies its position at the forefront of local AI, enhancing interactivity and enabling competition with cloud models, especially in privacy-sensitive or offline scenarios. The industry anticipates that Ollama's continuous innovation will foster the widespread adoption of local AI, particularly in education, research, and enterprise applications.
While some feedback indicates potential instability in tool invocation under high-temperature settings and the lack of streaming parameters in OpenAI-compatible endpoints, these challenges signal the rapid evolution of the technology, with future versions expected to address these issues.
In conclusion, Ollama v0.8 breathes new life into local AI with features like streaming, tool invocation, and performance optimizations. From real-time web searches to efficient model execution, this open-source framework is redefining AI development and application.