The world of artificial intelligence is evolving rapidly, and Ollama’s latest release, version 0.8, is a testament to this progress. This new iteration of the Ollama framework is set to transform the way large language models (LLMs) are deployed locally, offering a range of innovative features that enhance both functionality and user experience. Let’s explore the key advancements that make Ollama v0.8 a game-changer in the AI landscape.
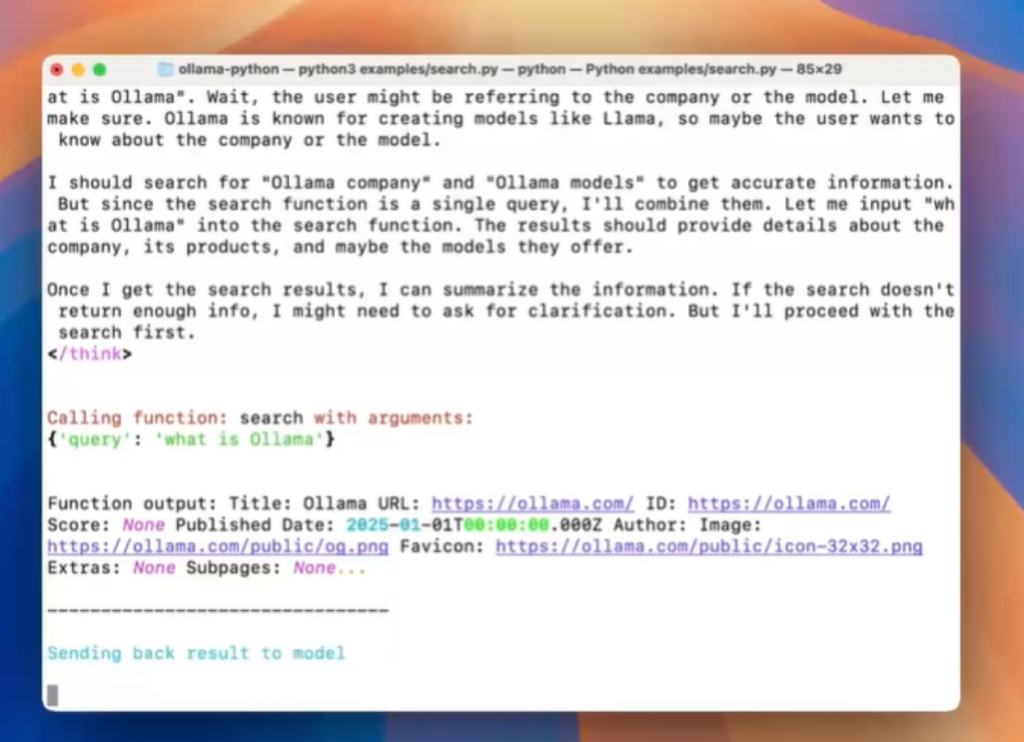
Imagine a scenario where you’re working with an AI model, and instead of waiting for a complete response, you can see the output unfold step by step in real time. This is precisely what Ollama v0.8 delivers with its streaming response feature. Users can now interact with AI models in a more dynamic and efficient manner, receiving immediate feedback during conversations or task processing. This real-time interaction is particularly valuable for complex queries or extensive text generation, as it allows users to observe the AI’s thought process without delay.
In practical applications, such as web searches, Ollama v0.8 takes this a step further. It can display the generation of search results in real time, enabling users to access the latest information quickly. This not only boosts efficiency but also opens up new possibilities for interactive learning, research, and content creation. The ability to see results as they are being generated makes the entire process more engaging and responsive.
But Ollama v0.8 doesn’t stop at enhancing user interaction. It also bridges the gap between local AI models and the external world through its tool calling feature. This functionality allows locally running language models to interact with external tools and data sources via APIs. For example, an AI model can call a web search API to fetch real-time data or connect to databases and third-party services to perform more complex tasks. This integration transforms local AI from a static system into a dynamic, real-time intelligent assistant capable of handling a wide range of applications.
Performance has also been a major focus in Ollama v0.8. The new version addresses several technical challenges, such as memory leaks in models like Gemma3 and Mistral Small3.1, and significantly improves model loading speeds. It performs exceptionally well on network-supported file systems like Google Cloud Storage FUSE. Additionally, the introduction of sliding window attention optimization enhances the long-context reasoning speed and memory allocation efficiency of Gemma3. These improvements ensure that Ollama v0.8 runs smoothly and efficiently, even on diverse hardware configurations.
Ollama v0.8 is more than just a technical upgrade; it is a powerful tool for developers and the broader AI community. As an open-source framework, it continues to promote openness and collaboration. The complete code and detailed documentation are available on GitHub, supporting a variety of mainstream models, including Llama3.3, DeepSeek-R1, Phi-4, Gemma3, and Mistral Small3.1. Developers can run these models locally using simple commands, eliminating the need for cloud APIs and balancing privacy with cost-effectiveness.
Moreover, Ollama v0.8 introduces preview support for AMD GPUs on Windows and Linux, and achieves initial compatibility with the OpenAI Chat Completions API. This compatibility allows developers to seamlessly integrate existing OpenAI tools with local models, further reducing barriers to entry and encouraging more developers to join the Ollama ecosystem.
The release of Ollama v0.8 marks a significant milestone in the field of local AI. By introducing streaming responses and tool calling capabilities, it enhances the interactivity of local models and enables them to compete with cloud-based solutions, especially in scenarios where privacy and offline access are critical. Industry experts predict that Ollama’s continuous innovation will drive the widespread adoption of local AI in education, research, and enterprise applications.
However, there is always room for improvement. Some feedback suggests that tool calling in Ollama v0.8 may become unstable under certain conditions, and the OpenAI-compatible endpoints do not yet support streaming parameters. These challenges highlight the ongoing rapid iteration of the technology, with future versions expected to address these issues and further optimize performance.
In conclusion, Ollama v0.8 represents a major step forward in the local deployment of large language models. With its real-time interaction capabilities, enhanced performance, and open-source approach, it is reshaping the way AI is developed and applied. As the technology continues to evolve, Ollama is poised to unlock new possibilities and drive innovation in the AI space.
Project address: Release v0.8.0 · ollama/ollama