 Bookmark this site
Bookmark this siteOver the past year, we have collaborated with dozens of teams to build numerous Large Language Model (LLM) Agents across various industries. The most successful implementations did not rely on complex frameworks or specialized libraries. Instead, they were constructed using simple, composable patterns.
In this article, we share the knowledge we've gained from working with clients and building Agents ourselves, offering practical advice for developers looking to construct effective Agents.
**What is an Agent?**
The term "Agent" can be defined in several ways. Some clients view Agents as fully autonomous systems that operate independently over extended periods, using various tools to accomplish complex tasks. Others describe them as more prescriptive implementations that follow predefined workflows. At Anthropic, we classify all these variations as Agentic systems, but we draw an important architectural distinction between workflows and Agents:
– Workflows are systems that orchestrate LLMs and tools through predefined code paths.
– Agents, on the other hand, are systems guided by LLMs to dynamically direct their own processes and tool usage, controlling how they complete tasks.
Below, we delve into these two types of Agent systems. In Appendix 1 ("Agents in Practice"), we describe two areas where clients find these systems particularly valuable.
**When (and When Not) to Use Agents**
When building applications with LLMs, we advise finding the simplest solution and increasing complexity only when necessary. This might mean not building an Agent system at all. Agent systems often trade off latency and cost for better task performance, and you should consider when this trade-off makes sense.
When more complexity is needed, workflows provide predictability and consistency for well-defined tasks, while Agents are a better choice for large-scale flexibility and model-driven decision-making. However, for many applications, optimizing individual LLM calls with retrieval and context examples is often sufficient.
**When and How to Use Frameworks**
There are numerous frameworks that can facilitate the implementation of Agent systems, including:
– LangChain's LangGraph;
– Amazon Bedrock's AI Agent framework;
– Rivet, a drag-and-drop GUI LLM workflow builder;
– Vellum, another GUI tool for building and testing complex workflows.
These frameworks lower the barrier to entry by simplifying standard low-level tasks, such as calling LLMs, defining and parsing tools, and linking different calls together. However, they often create additional layers of abstraction that may obscure underlying prompts and responses, making them harder to debug. They can also encourage increased complexity when simpler setups are sufficient.
We recommend that developers start by using LLM APIs directly: many patterns can be implemented with just a few lines of code. If you are using a framework, ensure you understand the underlying code. Misassumptions about the underlying content are a common source of errors for clients.
Please refer to our example cookbook (https://github.com/anthropics/anthropic-cookbook/tree/main/patterns/agents) for some sample implementations.
**Building Blocks, Workflows, and Agents**
In this section, we explore some common patterns observed in Agent systems in production. We start with the basic building block, an enhanced LLM, and gradually increase complexity, discussing simple composite workflows and autonomous Agents.
**Building Block: Enhanced LLM**
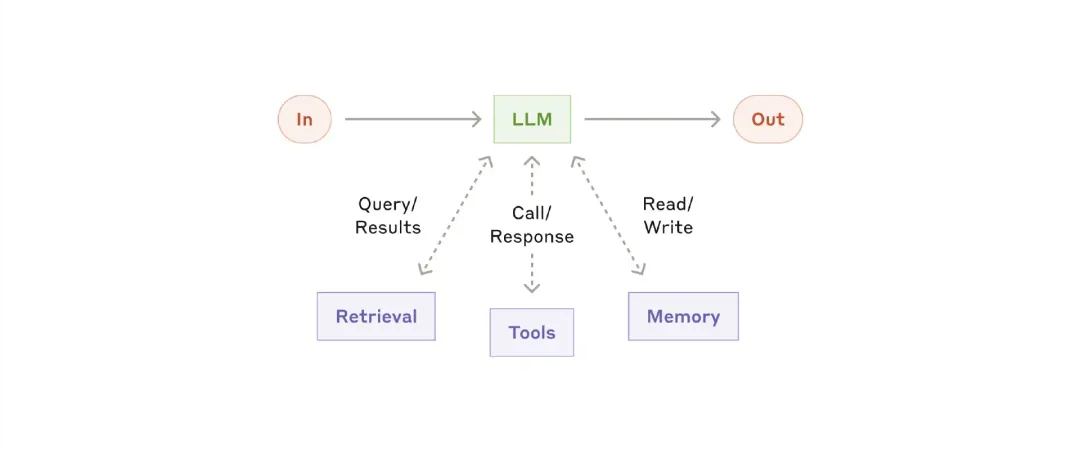
The fundamental building block of an Agent system is an LLM enhanced with capabilities such as retrieval, tools, and memory. Our current models can actively use these abilities, generating their own search queries, selecting appropriate tools, and determining which information to retain.
For this implementation, we recommend focusing on two key aspects: customizing these features according to your specific use case and ensuring they provide a simple, well-documented interface for your LLM. There are many ways to achieve these enhancements, one method being through our recently released model context protocol, which allows developers to integrate with an expanding ecosystem of third-party tools through simple client implementations.
For the rest of this article, we assume that each LLM call can access these enhanced capabilities.
**Workflow: Prompt Chaining**
Prompt chaining breaks down individual tasks into a series of steps, where each LLM call processes the output of the previous one. You can add programmatic checks at any intermediate step (see "gate" in the figure below) to ensure the process is still on track.
When to use this workflow: This workflow is well-suited for tasks that can be easily and cleanly divided into multiple fixed subtasks. The main goal here is to make each LLM call a simpler task, achieving higher accuracy at the cost of latency.
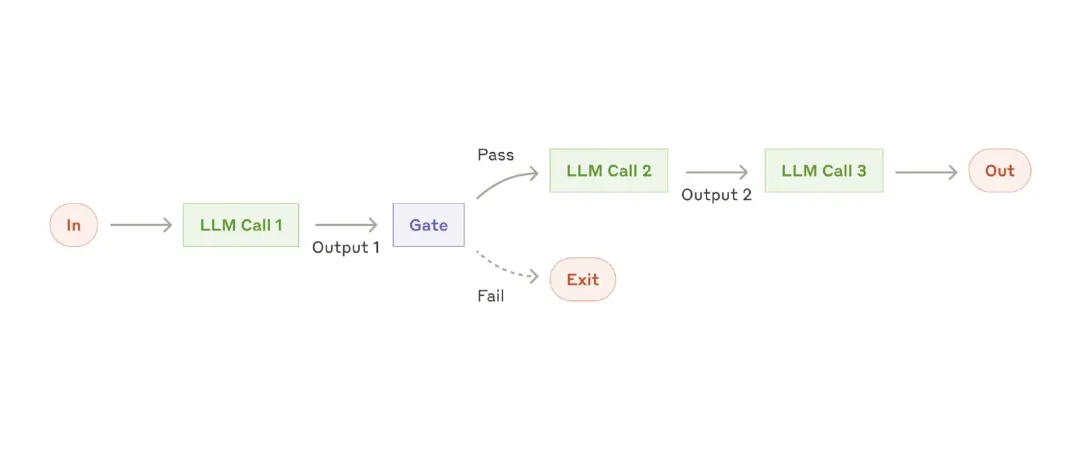
Examples suitable for prompt chaining:
– Generating marketing copy, then translating it into different languages.
– Writing a document outline, checking if the outline meets certain criteria, then writing the document based on the outline.
**Workflow: Routing**
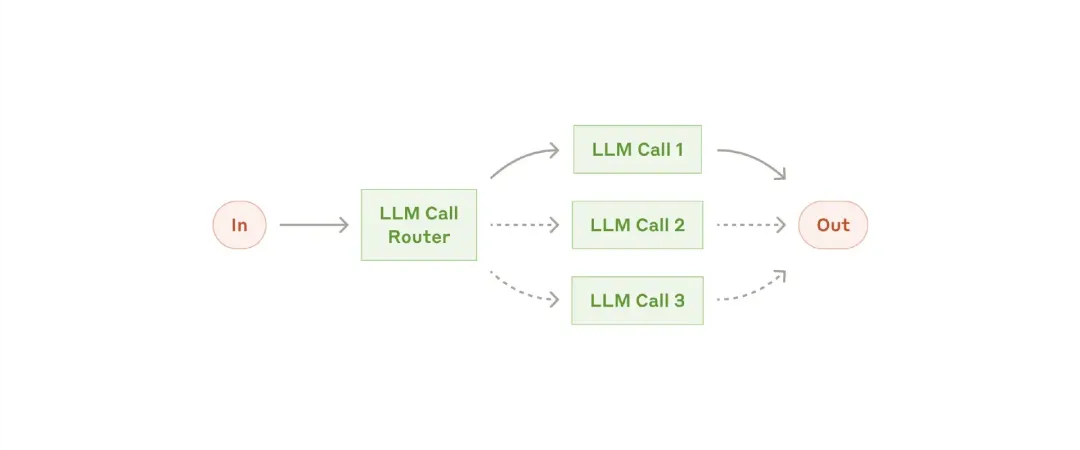
Routing classifies inputs and directs them to specialized subsequent tasks. This workflow can separate concerns and build more specialized prompts. Without this workflow, optimizing for one type of input may harm the performance of others.
When to use this workflow: Routing is excellent for complex tasks with different categories that are best handled separately and can be accurately classified by LLMs or more traditional classification models/algorithms.
Examples suitable for routing:
– Routing different types of customer service inquiries (general questions, refund requests, technical support) to different downstream processes, prompts, and tools.
– Routing simple/common questions to smaller models (e.g., Claude 3.5 Haiku) and difficult/unusual questions to more powerful models (e.g., Claude 3.5 Sonnet) to optimize cost and speed.
**Workflow: Parallelization**
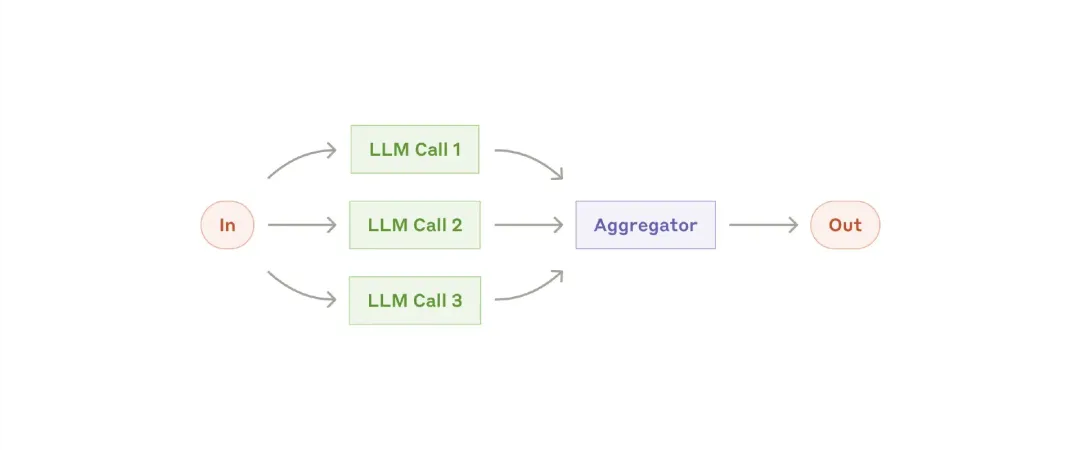
LLMs can sometimes handle a task concurrently and programmatically aggregate their outputs. This workflow (parallelization) has two key variants:
– Segmentation: Breaking a task into multiple independent subtasks that run in parallel.
– Voting: Running the same task multiple times to get different outputs.
When to use this workflow: Parallelization is effective when a task can be divided into multiple subtasks to increase speed or when a task requires multiple perspectives or attempts for higher confidence results. For complex tasks with multiple considerations, multiple LLMs often perform better when each LLM call handles a separate consideration, allowing each LLM to focus on a specific aspect.
Examples suitable for parallelization:
– Segmentation:
Implementing guardrails, where one model instance handles user queries while another filters inappropriate content or requests. This often works better than having the same LLM call handle guardrails and core responses simultaneously.
Automatically evaluating LLM performance, where each LLM call assesses different aspects of model performance for a given prompt.
– Voting:
Reviewing a piece of code for vulnerabilities, where several different prompts review the code and mark it when issues are found.
Assessing whether given content is inappropriate, with multiple prompts evaluating different aspects or requiring different voting thresholds to balance false positives and false negatives.
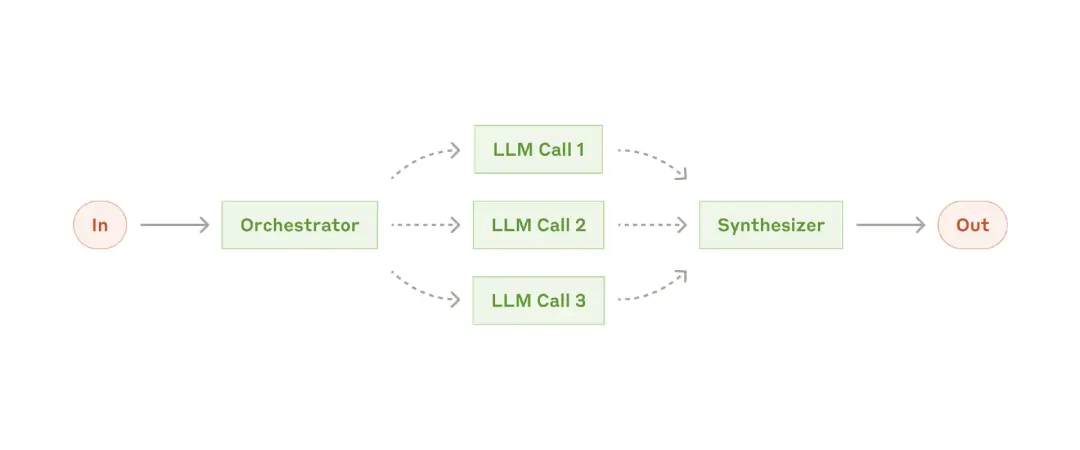
**Workflow: Orchestrator-Workers**
In the orchestrator-workers workflow, a central LLM dynamically breaks down tasks, delegates them to worker LLMs, and is responsible for synthesizing their results.
When to use this workflow: This workflow is well-suited for complex tasks where you cannot predict which subtasks are needed (e.g., in programming, the number of files that need changes and the parameters for each file may depend on the specific task). While it is topologically similar to parallelization, the main difference is its flexibility—subtasks are not predefined but determined by the orchestrator based on specific inputs.
Examples suitable for orchestrator-workers:
– Programming products that require complex changes to multiple files each time.
– Search tasks that need to collect and analyze information from multiple sources to get potentially relevant information.
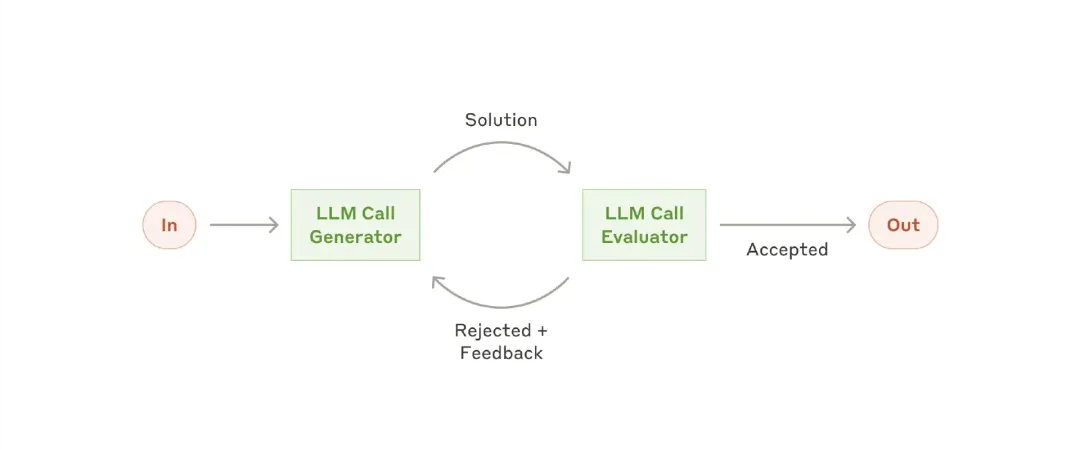
**Workflow: Evaluator-Optimizer**
In the evaluator-optimizer workflow, one LLM call generates a response while another provides evaluations and feedback in a loop.
When to use this workflow: This workflow is particularly useful when there are clear evaluation criteria and iterative improvements provide measurable value. Two signs that it is very suitable are: first, when human-expressed feedback can significantly improve LLM responses; second, when LLMs can provide such feedback. This is similar to the iterative writing process a human author might go through when crafting a fine document.
Examples suitable for evaluator-optimizer:
– Literary translation, where there are nuances that an LLM translator might not initially capture but an LLM evaluator can provide useful criticism.
– Complex search tasks that require multiple rounds of searching and analysis to gather comprehensive information, with the evaluator deciding whether further searches are necessary.
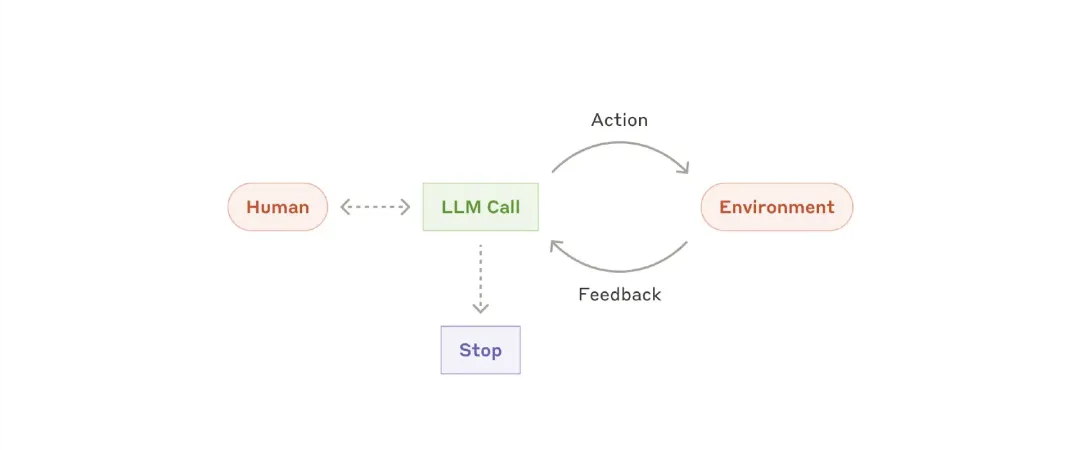
**Agent**
As LLMs mature in key capabilities—understanding complex inputs, engaging in reasoning and planning, reliably using tools, and recovering from errors—Agents are being deployed in production environments. Agents start with human user commands or interactive discussions with human users. Once the task is clarified, Agents plan and operate independently and may return to humans for more information or judgment. During execution, Agents must obtain "ground truth" from the environment at each step (e.g., tool call results or code execution) to assess their progress. Then, Agents can pause at checkpoints or when encountering obstacles to get human feedback. Tasks usually terminate after completion but often include stop conditions (e.g., maximum number of iterations) to maintain control.
Agents can handle complex tasks, but their implementations are often simple. They are typically just LLMs that use tools based on environmental feedback. Therefore, designing the tool set and its documentation clearly and thoughtfully is crucial. We expand on best practices for tool development in Appendix 2 ("Prompt Engineering for Your Tools").
**Autonomous Agent**
When to use Agents: Agents can be used for open-ended questions where it is difficult or impossible to predict the number of steps required, and you cannot hard-code a fixed path. LLMs may run many rounds, and you must trust their decisions to some extent. Agent autonomy makes it an ideal choice for expanding tasks in trusted environments.
Agent autonomy means higher costs and the potential for compounding errors. We recommend extensive testing in sandbox environments and appropriate safeguards.
Examples suitable for Agents:
– The following examples are from our own implementations:
A programming Agent for solving SWE-bench tasks, which requires editing many files based on task descriptions;
Our "computer usage" reference implementation, where Claude uses a computer to complete tasks.
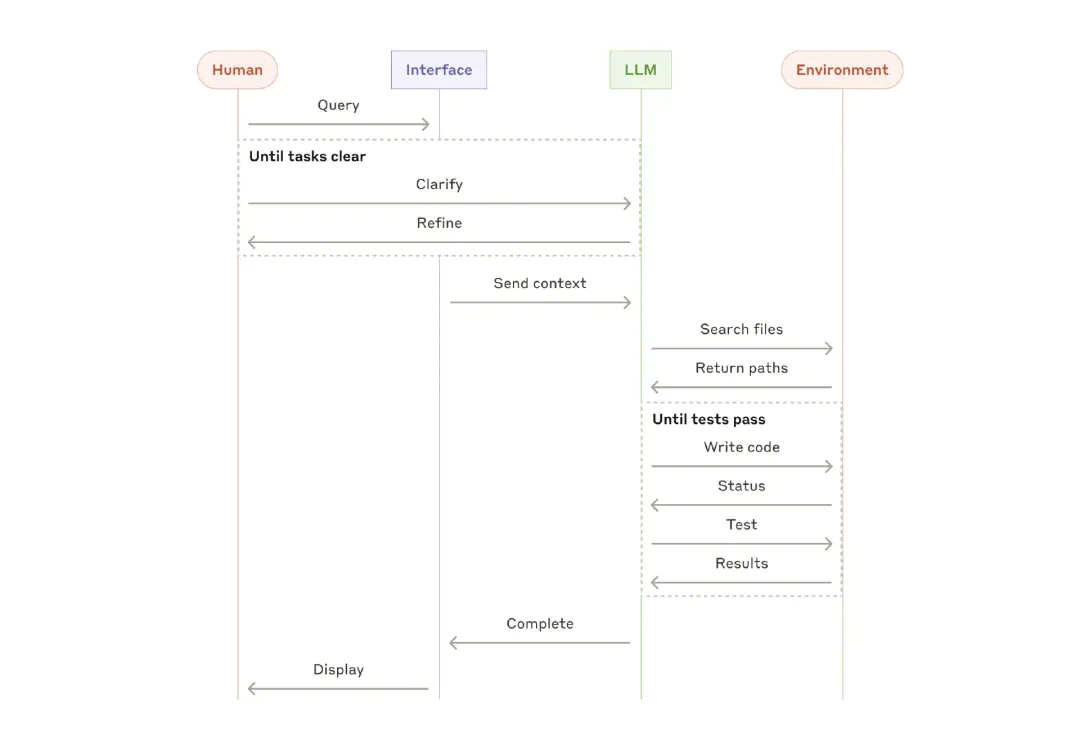
**A High-Level Process for a Programming Agent**
These building blocks are not rigid. They are common patterns that developers can shape and combine to fit different use cases. As with any LLM functionality, the key to success is measuring performance and iterating implementations. Repeat: only consider increasing complexity when more complexity can significantly improve results.
**Conclusion**
Success in the LLM field is not about building the most complex systems but about constructing systems that fit your needs. Start with simple prompts, optimize them through comprehensive assessments, and only add multi-step Agent systems when simpler solutions fall short.
When implementing Agents, we try to follow three core principles:
– Maintain the simplicity of Agent design.
– Prioritize transparency by clearly showing Agent planning steps.
– Carefully design the Agent-Computer Interface (ACI) through comprehensive tool documentation and testing.
Frameworks can help you get started quickly, but when it comes to production, decisively reduce abstraction layers and build with basic components. By following these principles, you can create powerful, reliable, maintainable, and trusted Agents.
**Appendix 1: Agents in Practice**
Our collaborations with clients have revealed two particularly promising AI Agent applications that demonstrate the practical value of the patterns discussed above. Both applications illustrate how Agents can add value to tasks that require conversation and action, have clear success criteria, enable feedback loops, and integrate well with human supervision.
A. Customer Support
Customer support combines a familiar chatbot interface with a range of enhanced features through integrated tools. This naturally suits a more open-ended Agent because:
– Customer support interactions naturally follow conversational flows while needing access to external information and operations;
– Tools can be integrated to extract customer data, order histories, and knowledge base articles;
– Operations such as issuing refunds or updating tickets can be handled programmatically;
– Success metrics can be clearly measured through user-defined solutions.
Several companies have proven the viability of this approach through usage-based pricing models, charging only for successful solutions, demonstrating confidence in their Agent efficiency.
B. Programming Agent
The software development field has shown significant potential for LLMs, with capabilities evolving from simple code autocompletion to autonomous problem-solving. Agents are particularly effective because:
– Code solutions can be verified through automated testing;
– Agents can use test results as feedback to iterate solutions;
– The problem space is well-defined and structured;
– Output quality can be objectively measured.
In our own implementation, Agents can now solve real GitHub issues from the SWE-bench Verified benchmark based solely on pull request descriptions. However, while automated testing aids in verifying functionality, human review remains crucial to ensure solutions meet broader system requirements.
**Appendix 2: Prompt Engineering for Your Tools**
Regardless of the type of Agent system you build, tools can be a significant component of an Agent. Tools specify the exact structure and definition of external services and APIs in our API, allowing Claude to interact with external services and APIs. When Claude responds, if it plans to call a tool, it includes a tool usage block in the API response. Tool definitions and specifications should receive as much prompt engineering attention as your overall prompts. In this brief appendix, we describe how to perform prompt engineering for your tools.
The same operation can often be specified in several ways. For example, you can specify a file editing operation by writing a diff or rewriting the entire file. For structured output, you can return code in markdown or JSON. In software engineering, these differences are superficial and can be converted无损地 from one to another. However, for LLMs, some formats are more challenging to write than others. Writing a diff requires knowing how many lines have changed in the block header before writing new code. Writing code in JSON (compared to markdown) requires additional escaping of newline characters and quotes.
Our recommendations for choosing tool formats are as follows:
– Give the model enough tokens to "think" before it gets stuck.
– Make the format as close as possible to what the model naturally encounters on the internet.
– Ensure there is no formatting "overhead," such as having to accurately count thousands of lines of code or escape strings for any code written.
– A rule of thumb is to consider how much effort is required for human-computer interfaces (HCI) and plan to invest the same amount of effort in creating a good Agent-Computer Interface (ACI). Here are some suggestions on how to do this:
– Put yourself in the model's shoes. Is the tool's usage obvious based on the description and parameters, or does it require careful consideration? If it's the latter, the model may feel the same. A good tool definition typically includes example usage, edge cases, input format requirements, and clear boundaries with other tools.
– How can you change parameter names or descriptions to make things more apparent? Consider this step as writing excellent documentation for junior developers on your team. This is especially important when using many similar tools.
– Test how the model uses your tool: run many example inputs in our playground to see what mistakes the model makes, then iterate.
– Make your tool less prone to errors. Change parameters to make it harder to make mistakes.
When building Agents for SWE-bench, we actually spent more time optimizing our tools than the overall prompts. For example, we found that tools using relative file paths would cause the model to make mistakes when the Agent moved out of the root directory. To address this, we changed the tool to always require absolute file paths—we found that the model used this method flawlessly.