Claude 3: A New Generation of AI Models
Anthropic, a major competitor to OpenAI, has recently unveiled Claude 3, the latest series of AI large models. The series includes three models with varying capabilities: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus, ranging from the least to the most powerful.
Comparing Claude 3 to GPT-4
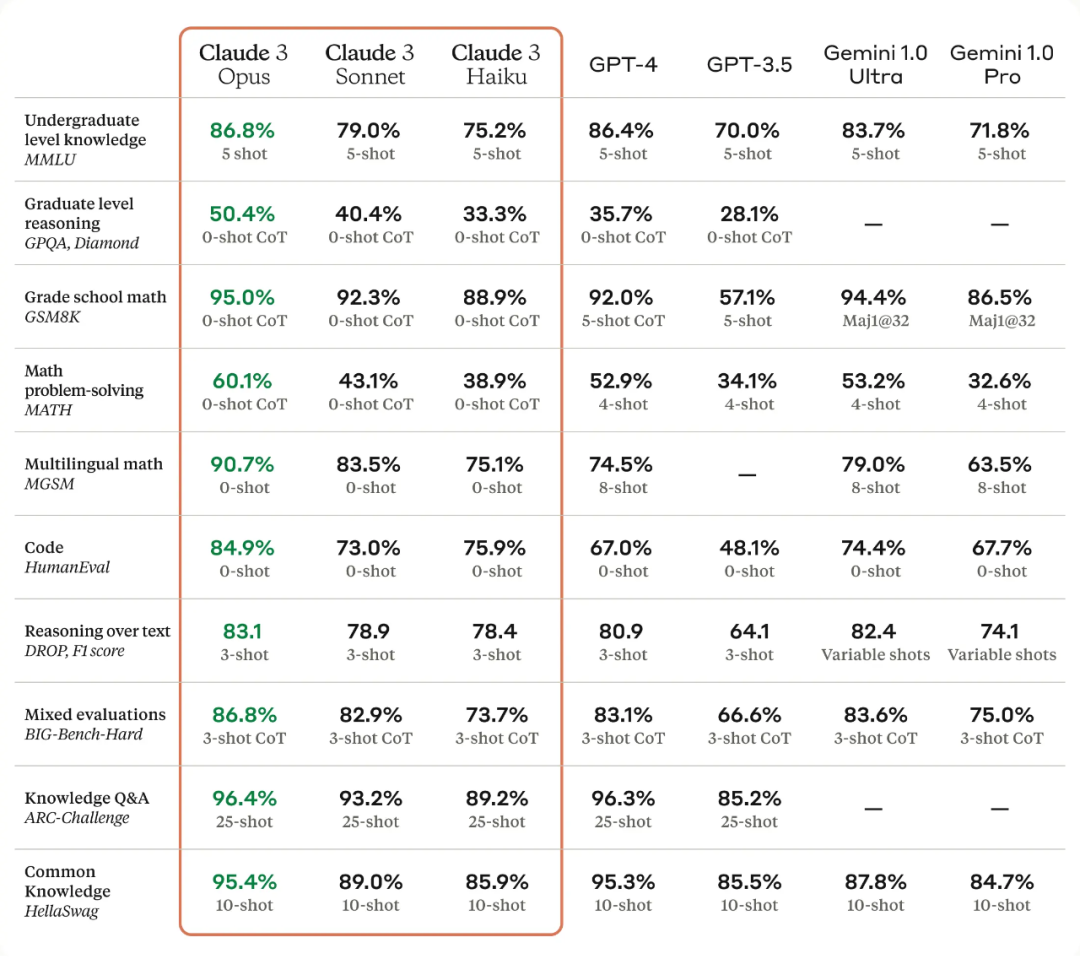
According to Anthropic, Claude 3 Haiku is the fastest model, designed for scenarios requiring immediate responses. It can read information and data-dense research papers on arXiv, including diagrams and graphics, in less than three seconds (approximately 10k tokens). Claude 3 Sonnet offers a balance between intelligence and speed, suitable for enterprise workloads like knowledge retrieval or sales automation. The most capable model, Claude 3 Opus, achieves near-human understanding and is suited for highly complex tasks. It has outperformed GPT-4 and Gemini 1.0 Ultra in multiple benchmarks, setting new industry standards in mathematics, programming, multilingual understanding, and vision.
Benchmark Test Data and Performance
Anthropic's benchmark test data shows that Opus outperforms GPT-4 in several metrics. Before this, GPT-4 was globally leading in overall performance, with only Claude 2 from the previous generation surpassing GPT-3.5. Claude 3 not only excels in speed, understanding, and efficiency but also stands out in handling long texts, supporting up to 200K Tokens context length and image and file input capabilities.
Pricing and Technical Report
The pricing for the Claude 3 models is as follows: Opus at $15 per million tokens for input and $75 per million tokens for output; Sonnet at $3 per million tokens for input and $15 per million tokens for output; Haiku at $0.25 per million tokens for input and $1.25 per million tokens for output. Anthropic has also released a 42-page technical report titled "The Claude 3 Model Family: Opus, Sonnet, Haiku," detailing the training data, evaluation criteria, and more detailed experimental results of the Claude 3 series models.
Comparing Reasoning, Reading Comprehension, Mathematics, Science, and Programming Capabilities
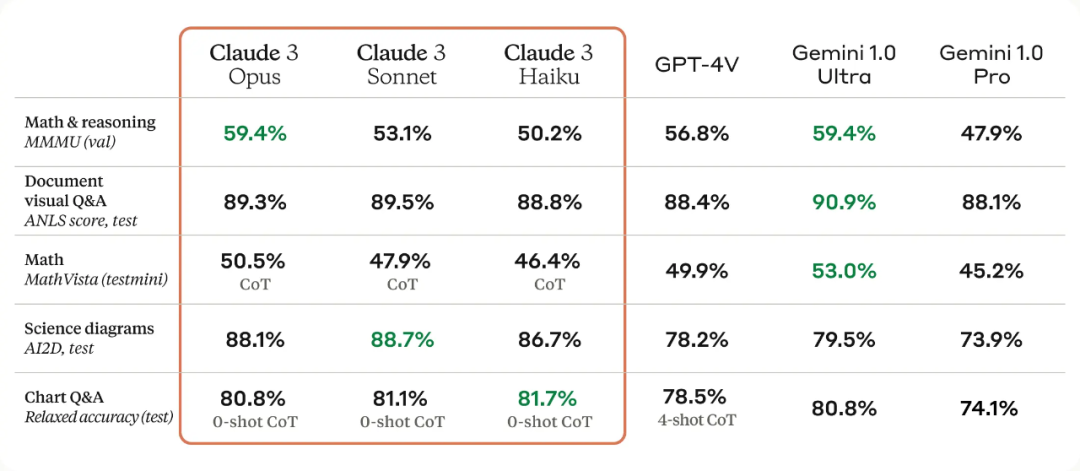
Anthropic compared the Claude 3 series models with competitive models in reasoning, reading comprehension, mathematics, science, and programming capabilities. The results show that not only did they surpass other models, but they also achieved new SOTA in most cases.
User Testing and Validation

While Anthropic claims that their models are stronger than GPT-4, many users are skeptical about benchmark tests. They argue that benchmark tests are less reliable, as they compare Claude 3 to GPT-4, which was released a year ago, and the selected metrics may favor Anthropic.
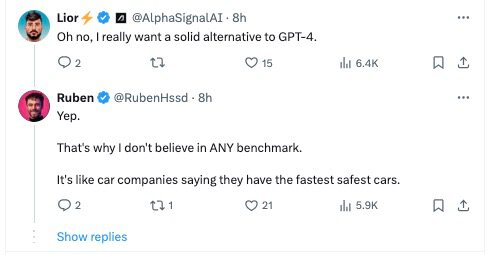
Users have conducted their tests to verify the capabilities of Claude 3. One user noted that it seemed slightly better than GPT-4 and significantly better than Mistral. A particularly human-like response from Claude 3 was highlighted, where the model used capitalization for emphasis in a comforting message, something GPT-4 would not do without prompting.
Innovative ASCII Communication
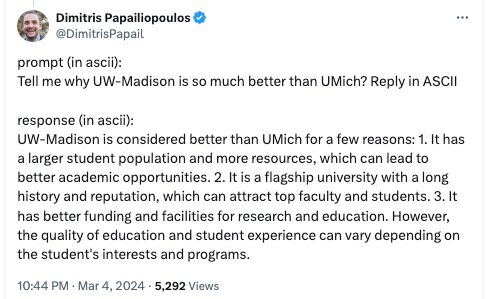
A user creatively asked questions in ASCII format, and Claude 3 responded in ASCII as well, demonstrating its ability to read and reply in ASCII code.
Code Capability Tests
Users have also tested Claude 3's coding capabilities. One user asked Claude 3 to create a 3D self-portrait and render it into code, resulting in an impressive outcome.
Moral Standards and Code Conversion

A user named Ruben set up a test to compare Claude 3 and ChatGPT's abilities. He provided a website UI interface and asked both to convert it into code. Claude 3 refused, while ChatGPT successfully executed the task, raising questions about Claude 3's high moral standards.
SQL-Eval Assessment
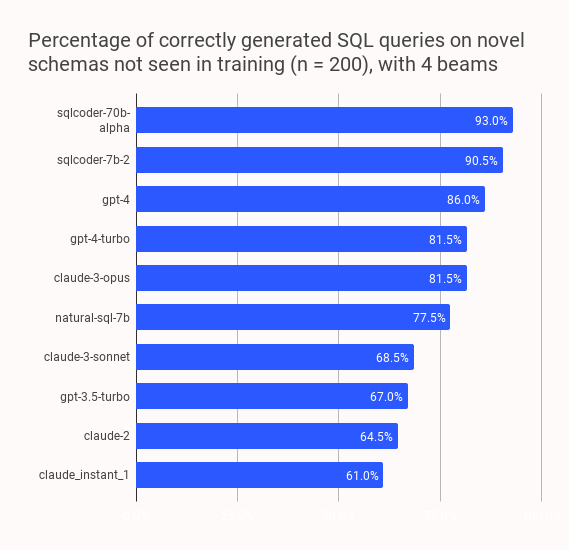
An entrepreneur, Rishabh Srivastava, assessed Claude-3 on SQL-Eval and concluded that GPT-4 is still better. He stated that while Opus has GPT-4 Turbo-level performance for SQL generation, Sonnet has similar performance to 3.5-turbo but is about four times slower. GPT-4 remains significantly better.
Final Analysis
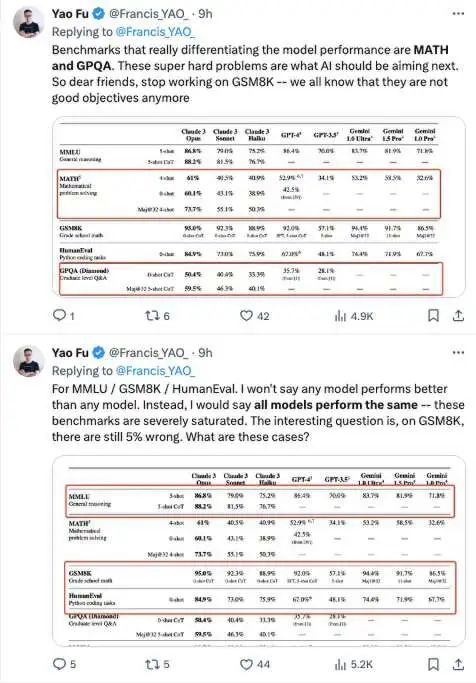
As analyzed by Ph.D. student Fu Yao from the University of Edinburgh, the models evaluated show little distinction in MMLU, GSM8K, and HumanEval metrics. The real differentiators are MATH and GPQA, which are the super challenging problems that AI models should target next.