Tencent Cloud has taken a significant step in democratizing AI by launching the Hunyuan-A13B model's API service, priced at 0.5 yuan per million Tokens for input and 2 yuan per million Tokens for output. This move has sparked a flurry of excitement among developers, as it marks the debut of the industry's first 13B-level MoE (Mixture of Experts) open-source mixed inference model.
Hunyuan-A13B boasts a total of 80B parameters, with only 13B being active, offering a lean yet powerful design that rivals leading open-source models in its architecture. Its superior inference speed and enhanced cost-effectiveness have lowered the barrier for developers to access advanced model capabilities, laying a solid foundation for the widespread adoption of AI applications.
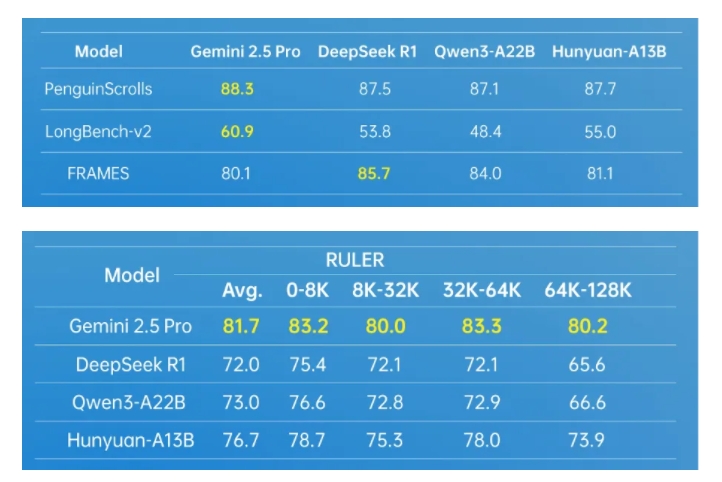
The model's advanced architecture design has demonstrated formidable versatility, achieving outstanding results across multiple authoritative industry datasets. It excels particularly in Agent tool invocation and long-form text processing. To further enhance Agent capabilities, Tencent's Hunyuan team has developed a multi-Agent data synthesis framework. This framework integrates diverse environments such as MCP, sandboxing, and large language model simulation, employing reinforcement learning to enable Agents to explore and learn autonomously, significantly improving the model's practicality and effectiveness.
In terms of long-form text processing, Hunyuan-A13B supports a native context window of 256K, maintaining excellent performance across various long-text datasets. It also introduces an innovative fusion reasoning mode, allowing users to toggle between quick and slow thinking modes based on task requirements. This ensures output efficiency while catering to the accuracy needs of specific tasks, optimizing the allocation of computational resources.
For individual developers, Hunyuan-A13B is highly user-friendly. Under strict conditions, it can be deployed with just one mid-to-low-end GPU card. The model has seamlessly integrated into the mainstream open-source inference framework ecosystem, supporting various quantization formats. It boasts a吞吐量 more than twice that of cutting-edge open-source models under the same input-output scale, showcasing its exceptional performance and flexibility.
The success of the Hunyuan-A13B model is attributed to the innovative techniques employed by the Tencent Hunyuan team during pre-training and post-training phases. During pre-training, the team trained a corpus of up to 20T tokens, covering multiple domains, significantly enhancing the model's versatility. They also constructed a Scaling Law joint formula applicable to MoE architecture through systematic analysis and modeling validation, providing quantifiable engineering guidance for MoE design. The post-training phase involved a multi-stage training approach, further improving the model's inference capabilities and versatility.
As one of Tencent's largest internal applications and most frequently used large language models, Hunyuan-A13B has been widely applied across over 400 business scenarios, with a daily request volume exceeding 130 million times. This underscores its value and stability in practical applications.