In the rapidly evolving landscape of artificial intelligence, the Natural Language Processing team at the Institute of Computing Technology, Chinese Academy of Sciences, has unveiled a groundbreaking multimodal large model called Stream-Omni. This innovative model stands out for its ability to support multiple modalities of interaction, providing users with a more flexible and enriched experience.
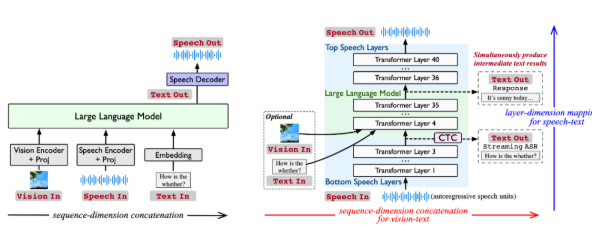
Stream-Omni is a multimodal large model based on the GPT-4o architecture, showcasing exceptional capabilities across text, vision, and speech modalities. With its online speech service, users can engage in voice interactions while simultaneously obtaining real-time intermediate text results, making the interaction experience more natural, akin to "seeing and hearing" at the same time.
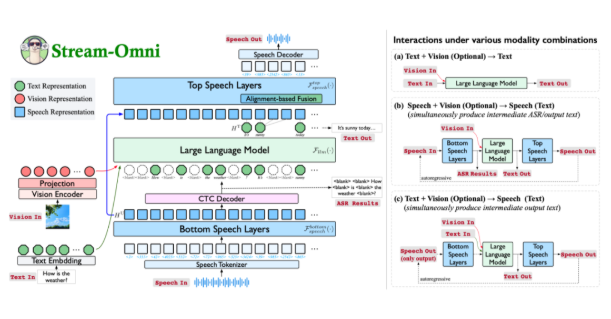
Traditional multimodal large models typically rely on concatenating representations from different modalities to generate responses in large language models. However, this approach is data-intensive and lacks flexibility. Stream-Omni addresses these limitations by focusing on targeted modeling of modality relationships, reducing the dependence on large-scale trimodal data. It emphasizes semantic consistency between speech and text and makes visual information semantically complementary to text, enabling more efficient modality alignment.
Stream-Omni's unique speech modeling approach allows it to output intermediate text transcription results during voice interactions, just like GPT-4o. This design provides users with a more comprehensive multimodal interaction experience, especially in scenarios requiring real-time voice-to-text conversion, significantly enhancing efficiency and convenience.
The design of Stream-Omni allows for flexible combinations of visual encoders, speech layers, and large language models, supporting various modality combinations for interaction. This flexibility enables users to freely choose the input method in different scenarios, whether text, voice, or vision, and receive consistent responses.
In multiple experiments, Stream-Omni's visual understanding capabilities are comparable to those of similarly scaled vision large models, while its speech interaction capabilities significantly outperform existing technologies. This hierarchical speech-text mapping mechanism ensures precise semantic alignment between speech and text, making responses across different modalities more consistent.
Stream-Omni not only offers new insights into multimodal interactions but also promotes the deep integration of text, vision, and speech technologies with its flexible and efficient features. Although there is still room for improvement in anthropomorphic performance and timbre diversity, it undoubtedly lays a solid foundation for future multimodal intelligent interactions.
For more information, refer to the paper: https://arxiv.org/abs/2506.13642
Explore the open-source code: https://github.com/ictnlp/Stream-Omni
Download the model: https://huggingface.co/ICTNLP/stream-omni-8b